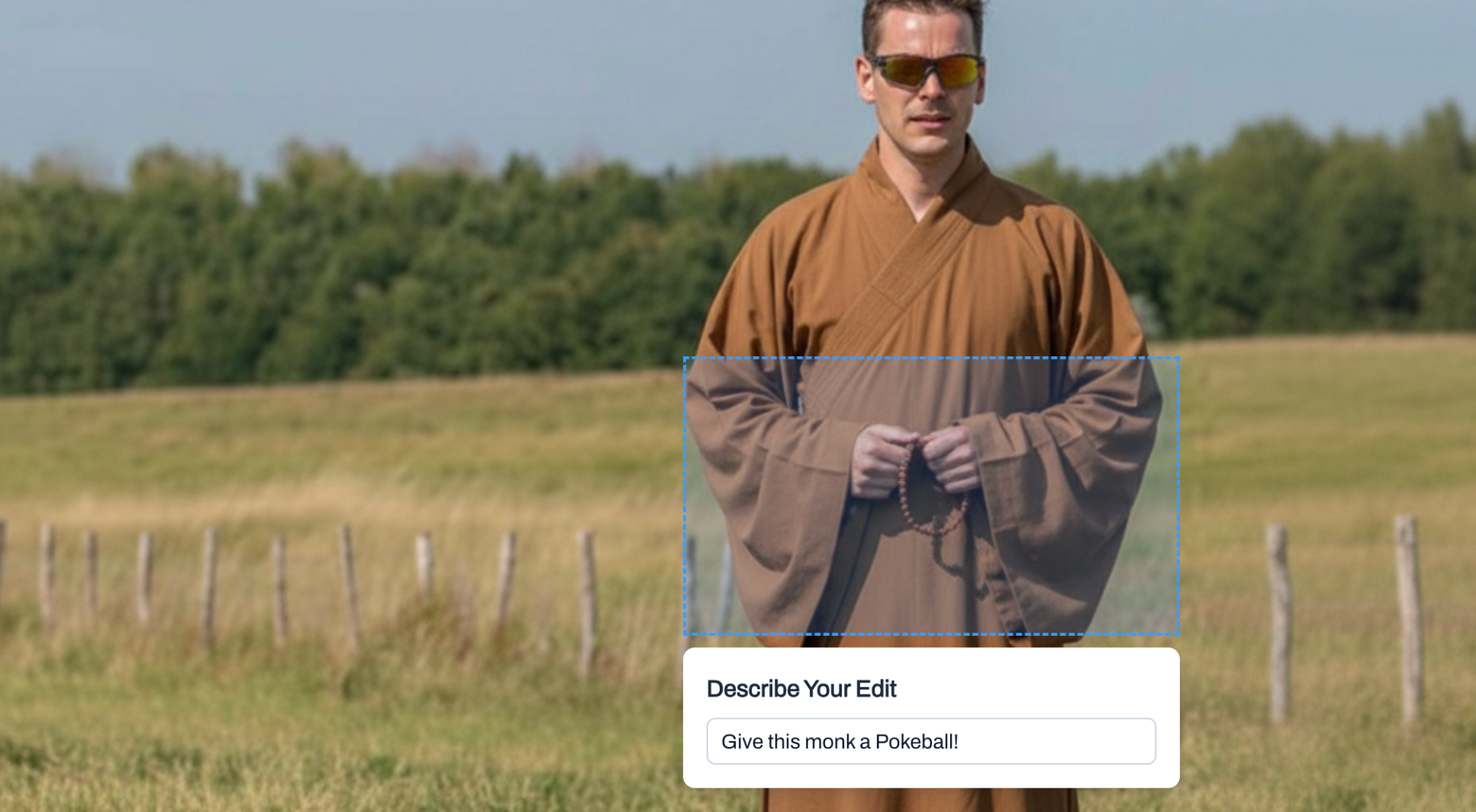
Learn how to build an image editor that modifies specific regions using Gemini's image generation API, with practical TypeScript and Vue.js implementations.
Table of Contents
Introduction
You've probably seen AI image generators that can create entire images from text prompts. But what if you only want to change one small part of an existing photo? Maybe you need to swap out a background, adjust lighting in one corner, or replace an object while keeping everything else pixel-perfect.
Building this kind of surgical image editing turns out to be surprisingly tricky. You can't just ask an AI to "change the sky" and expect it to respect the exact boundaries and lighting of your original image. We need a system that extracts a specific region, modifies it with precise instructions, then composites it back seamlessly.
In this article, we'll build a fine-grained image editor using Google's Gemini 2.5 Flash with image generation capabilities. You'll learn how to handle region selection, convert image data between formats for API calls, and composite AI-generated slices back into the original. We'll start with vanilla TypeScript, then see how Vue simplifies the state management and user interaction.
The Core Concept
Traditional image editing with AI typically works on the entire image at once. You send a photo and get back a completely new image. This works great for generating art from scratch, but it's terrible for targeted edits where you want surgical precision.
Fine-grained editing flips this around. Instead of sending the whole image, we extract just the rectangular region we want to modify. We send that slice to the AI with very specific instructions about what to change and what to preserve. The AI returns a modified version of just that slice, which we then overlay back onto the original image at the exact same coordinates.
The tricky part is coordinate mapping. When users select a region on their screen, we're working in CSS pixels. But the actual image has its own natural dimensions. An image displayed at 400px wide might actually be 1920px wide in its original form. We need to track both the display coordinates (for showing the selection box) and the natural coordinates (for extracting the right pixels).
Another challenge is aspect ratio control. If we want the AI to generate a 16:9 slice that fits back perfectly, we need to constrain the selection box to that ratio as users drag. We also need to tell the API exactly what ratio we want, otherwise it might return an image with different dimensions that won't align.
Implementation: Vanilla TypeScript
Let's start by handling image selection with aspect ratio constraints. We'll track two coordinate systems: client space (where the mouse moves) and natural image space (where we'll extract pixels).
<script setup lang="ts">
const test = ref('');
</script>
import { ref } from 'vue'
interface Selection {
x: number
y: number
width: number
height: number
}
let clientSelection: Selection | null = null
let naturalSelection: Selection | null = null
This separation is crucial. The clientSelection drives the UI overlay, while naturalSelection tells us which pixels to extract.
When the user drags to select a region, we need to constrain the box to maintain the chosen aspect ratio:
function updateSelection(
startX: number,
startY: number,
currentX: number,
currentY: number,
targetRatio: number
) {
const dx = currentX - startX
const dy = currentY - startY
let width = Math.abs(dx)
let height = width / targetRatio
We calculate width from horizontal movement, then derive height from the ratio. If the resulting height would be too tall, we flip it:
if (height > Math.abs(dy)) {
height = Math.abs(dy)
width = height * targetRatio
}
return { x: startX, y: startY, width, height }
}
Once the user finishes selecting, we map from client coordinates to natural image coordinates:
function mapToNaturalCoords(
selection: Selection,
imgElement: HTMLImageElement,
containerRect: DOMRect
): Selection {
const imgRect = imgElement.getBoundingClientRect()
const scaleX = imgElement.naturalWidth / imgRect.width
const scaleY = imgElement.naturalHeight / imgRect.height
The scale factors tell us how many actual pixels correspond to each displayed pixel. We use these to transform our selection:
return {
x: Math.round(selection.x * scaleX),
y: Math.round(selection.y * scaleY),
width: Math.round(selection.width * scaleX),
height: Math.round(selection.height * scaleY)
}
}
Now we can extract that region as a PNG blob:
async function extractSlice(
img: HTMLImageElement,
region: Selection
): Promise<Blob> {
const canvas = document.createElement('canvas')
canvas.width = region.width
canvas.height = region.height
const ctx = canvas.getContext('2d')
ctx.drawImage(img, region.x, region.y,
region.width, region.height, 0, 0,
region.width, region.height)
The canvas API's drawImage with all those parameters says "take this rectangular region from the source and draw it at this position with these dimensions on the canvas." We're copying a slice.
return new Promise(resolve => {
canvas.toBlob(blob => resolve(blob!), 'image/png')
})
}
To send the slice to Gemini's API, we need it as base64:
async function blobToBase64(blob: Blob): Promise<string> {
return new Promise((resolve) => {
const reader = new FileReader()
reader.onload = () => {
const dataUrl = reader.result as string
const base64 = dataUrl.split(',')[1]
resolve(base64)
}
reader.readAsDataURL(blob)
})
}
Now for the AI call. We need to be very specific in our prompt to prevent the model from being creative:
import { GoogleGenAI } from '@google/genai'
async function modifySlice(
imageData: string,
prompt: string,
aspectRatio: string,
dimensions: { width: number, height: number }
): Promise<string> {
const instruction = `You are an image editor.
Modify only the provided image slice according to: "${prompt}".
Keep all other pixels, composition, geometry, lighting, and style unchanged.
Do not generate a new scene, do not crop, and do not alter borders.`
The instruction is deliberately constrained. We're fighting against the model's tendency to "improve" things we didn't ask for.
const ai = new GoogleGenAI({ apiKey: process.env.GOOGLE_API_KEY })
const response = await ai.models.generateContent({
model: 'gemini-2.5-flash-image',
contents: [{
role: 'user',
parts: [
{ text: `${instruction} Output ${dimensions.width}x${dimensions.height}.` },
{ inlineData: { data: imageData, mimeType: 'image/png' } }
]
}],
config: {
responseModalities: ['IMAGE'],
imageConfig: { aspectRatio }
}
})
The responseModalities: ['IMAGE'] tells Gemini we want an image back, not text. The aspectRatio in the config ensures dimensional consistency.
const imagePart = response.candidates[0].content.parts
.find(p => p.inlineData?.mimeType?.startsWith('image/'))
return `data:image/png;base64,${imagePart.inlineData.data}`
}
Finally, we composite the modified slice back into the original:
async function compositeImages(
baseImg: HTMLImageElement,
modifiedSliceUrl: string,
region: Selection
): Promise<Blob> {
const modImg = await loadImage(modifiedSliceUrl)
const canvas = document.createElement('canvas')
canvas.width = baseImg.naturalWidth
canvas.height = baseImg.naturalHeight
We create a canvas the size of the original image, draw the base, then overlay the modified slice:
const ctx = canvas.getContext('2d')
ctx.drawImage(baseImg, 0, 0)
ctx.drawImage(modImg, 0, 0, modImg.naturalWidth,
modImg.naturalHeight, region.x, region.y,
region.width, region.height)
return new Promise(resolve => {
canvas.toBlob(blob => resolve(blob!), 'image/png')
})
}
Implementation: Vue.js
Vue makes the coordinate tracking and state management much cleaner. We can use refs to keep everything reactive:
const userImageFile = ref<File | null>(null)
const userImagePreviewUrl = ref<string | null>(null)
const imageElement = ref<HTMLImageElement | null>(null)
const imageContainerRef = ref<HTMLDivElement | null>(null)
const selectionRect = ref<Selection | null>(null)
const sliceMeta = ref<Selection | null>(null)
The distinction between selectionRect (client space) and sliceMeta (natural space) maps directly to our vanilla implementation. Vue's reactivity means any change automatically updates the UI.
For aspect ratio selection, we can use a reactive object:
interface RatioOption {
label: string
value: number
key: string
}
const selectedRatio = ref<RatioOption>({
label: '1:1',
value: 1,
key: '1:1'
})
Mouse handling becomes cleaner with Vue's template refs:
function handleMouseDown(event: MouseEvent) {
if (!imageContainerRef.value || !userImageFile.value) return
const rect = imageContainerRef.value.getBoundingClientRect()
const x = Math.min(Math.max(0, event.clientX - rect.left), rect.width)
const y = Math.min(Math.max(0, event.clientY - rect.top), rect.height)
startPoint.value = { x, y }
selectionRect.value = { x, y, width: 0, height: 0 }
}
The getBoundingClientRect() gives us the container's position, so we can convert client coordinates to container-relative coordinates. The Math.min(Math.max(...)) clamps values inside the container.
On mouse move, we update the selection while maintaining aspect ratio:
function handleMouseMove(event: MouseEvent) {
if (!isSelecting.value || !selectionRect.value) return
const ratio = selectedRatio.value.value
const dx = currentX - startPoint.value.x
const dy = currentY - startPoint.value.y
let width = Math.abs(dx)
let height = width / ratio
This is the same ratio math from vanilla, but now Vue automatically updates the UI overlay whenever selectionRect.value changes.
When the mouse goes up, we calculate natural coordinates:
async function handleMouseUp() {
const img = imageElement.value
const container = imageContainerRef.value
if (!img || !container || !selectionRect.value) return
const imgRect = img.getBoundingClientRect()
const containerRect = container.getBoundingClientRect()
const scaleX = img.naturalWidth / imgRect.width
const scaleY = img.naturalHeight / imgRect.height
Same coordinate mapping as before, but stored in a reactive ref:
sliceMeta.value = {
x: Math.round(adjustedX * scaleX),
y: Math.round(adjustedY * scaleY),
width: Math.round(adjustedWidth * scaleX),
height: Math.round(adjustedHeight * scaleY)
}
}
The AI call looks almost identical to vanilla, wrapped in a composable function:
async function generateModifiedSlice() {
if (!sliceMeta.value || !prompt.value) return
isGenerating.value = true
const { data } = await extractSlicePng()
const base64 = await toBase64Png(data)
const ai = getAi()
const response = await ai.models.generateContent({
model: 'gemini-2.5-flash-image',
contents: [/* same as vanilla */],
config: {
responseModalities: ['IMAGE'],
imageConfig: { aspectRatio: selectedRatio.value.key }
}
})
Vue's computed properties make the UI overlay positioning elegant:
const selectionStyle = computed(() => {
if (!selectionRect.value) return { display: 'none' }
return {
left: `${selectionRect.value.x}px`,
top: `${selectionRect.value.y}px`,
width: `${selectionRect.value.width}px`,
height: `${selectionRect.value.height}px`
}
})
Any time selectionRect changes, the computed updates and Vue re-renders the overlay. In the template:
<template>
<div
ref="imageContainerRef"
@mousedown="handleMouseDown"
@mousemove="handleMouseMove"
>
<img ref="imageElement" :src="userImagePreviewUrl" />
<div
v-if="selectionRect"
class="absolute border-2 border-dashed"
:style="selectionStyle"
/>
The selection box follows the mouse automatically because Vue tracks the reactive style object. No manual DOM manipulation needed.
For the modified slice overlay:
<img
v-if="modifiedSliceUrl && selectionRect"
:src="modifiedSliceUrl"
class="absolute object-fill"
:style="modifiedSliceStyle"
/>
</div>
</template>
The modified image appears at the exact same coordinates as the selection, creating the illusion of in-place editing.
Practical Considerations
Image generation APIs are expensive compared to text. Each Gemini image generation costs roughly 100× what a text completion does. If users are experimenting with multiple prompts on the same slice, those costs add up fast. Consider caching the original slice extraction and only re-generating when the prompt changes.
Latency is another issue. Image generation typically takes 5-15 seconds, which feels like forever if users don't see progress. You can't stream image generation like you can text, so good loading states are critical. Show the selection area with a loading overlay and keep the prompt visible so users remember what they asked for.
The quality of edits depends heavily on prompt engineering. Generic prompts like "make it better" produce inconsistent results. Specific prompts like "brighten the sky by 30% while keeping the horizon sharp" work much better. You might want to provide example prompts or a prompt builder to guide users toward success.
Aspect ratio mismatches will ruin the composite. Even if you specify a ratio in the API config, sometimes the returned image is slightly off. Always check the dimensions of the returned image and resize it to exactly match your target dimensions before compositing. Canvas drawImage with explicit width and height handles this scaling.
One gotcha I ran into: when working with large images (> 4000px wide), extracting slices can freeze the browser. Consider downscaling the image before extraction, running the AI generation on the smaller slice, then upscaling the result back to the original dimensions. The quality loss is usually acceptable for non-critical applications.
Wrapping Up
We've built a fine-grained image editor that modifies specific regions while preserving the rest of the image. The key insights are separating client and natural coordinate systems, using aspect ratio constraints during selection, and being very explicit in prompts to prevent unwanted creativity from the AI.
The vanilla TypeScript version shows the core mechanics: coordinate mapping, canvas manipulation, and API integration. Vue's reactive state and computed properties simplify the UI synchronization and make the code easier to reason about. Both approaches work, Vue just removes boilerplate.
From here, you could add undo/redo by tracking each modification as a layer, or implement multi-region editing where users select several areas before generating. The coordinate math stays the same, you're just managing more selections.

Extract Structured Data From PDFs With AI SDK
Build a PDF invoice parser that extracts text server-side and uses LLM structured outputs to convert unstructured invoice data into typed JSON objects
Generate Hyperrealistic Videos with Google's Veo 3.1
Learn how to generate photorealistic videos from text prompts using Google's Veo 3.1 text-to-video model with async polling